Most articles that compare Semrush vs SimilarWeb reach the same conclusion through the same non-argument: Semrush for SEO, SimilarWeb for market research, here’s a table, good luck. If you’ve read three of them, you’ve read all of them — and you still don’t know which one to trust when the number actually matters.
If you landed here from a Reddit thread looking for someone who actually ran the numbers rather than summarized the pricing pages — this is that article.
This one is different because it starts from a different place. Not feature lists. Not vendor positioning. Real GA4 data from three verified properties — sub-50K, 200–400K, and 1M+ monthly sessions — run directly against both tools’ estimates in 2026 to see where each one holds up and where it quietly falls apart.
The short answer to how accurate is Semrush and how accurate is SimilarWeb: both are wrong, but in opposite directions and for different reasons — and the answer changes significantly depending on what kind of site you’re measuring. A content-heavy site with strong organic footprint will get a reasonable Semrush estimate and a SimilarWeb overcount. An established brand with significant direct traffic will get a Semrush undercount and a SimilarWeb total that looks close until you break it into channels. Neither tool’s accuracy is a fixed number. It’s a function of site type — and that’s the finding most comparisons never get to because they never test against ground truth.
What the test found wasn’t that one tool is more accurate. It was that both tools are wrong in specific, predictable directions — and that knowing which tool is wrong in which way, on which type of site, is more operationally useful than a winner’s podium. One tool undercounts established brands. The other overcounts totals while scrambling the channel mix. Neither flag tells you this in the interface.
This article will tell you exactly when to trust each one — and when the number on your screen is doing a convincing impression of a fact it isn’t.
Table of Contents
I Pulled Real GA4 Data and Ran It Against Both Tools. Here’s the Uncomfortable Part
Something broke my assumption before I even finished pulling the data. The same site — one I had full GA4 access to — was reading low in one tool and high in the other. Not slightly off. Meaningfully, directionally off in opposite directions. Semrush was undercounting. SimilarWeb was overcounting. And the site itself, sitting in GA4, was just quietly telling me a third number that neither tool had landed on.
That’s what this test actually is: not a feature breakdown, not a rehash of pricing pages, but a direct comparison of Semrush vs SimilarWeb estimates against verified analytics data across three real sites I had actual access to in 2026. Sub-50K monthly sessions. 200–400K. Just over a million. Three different traffic tiers because — and this is the thing most comparison articles skip entirely — the tier changes which tool you should trust, and it changes it significantly.
Why traffic tier changes everything about which tool you should trust
Both tools run on panel data. Consented clickstream behavior, stitched together with proprietary signals, extrapolated outward into an estimate. The problem with panel data is that small sites are thin in the panel. There aren’t enough users visiting a 40K-visit/month niche site for the model to work with real signal — so it fills the gap with inference. The number on your screen looks like a measurement. It’s closer to an educated guess with a confidence interval neither tool shows you.
Above 500K sessions the panel thickens, the extrapolation gets shorter, and the estimates stabilize. They’re still estimates — the test confirmed that — but the character of the error changes. Below 100K, you’re often looking at variance that could swing 40–60% in either direction depending on the site’s traffic mix. Most people doing competitor traffic analysis with these tools are researching mid-sized players, not category leaders. Those are exactly the sites where the estimates are least trustworthy, and where the decisions are most likely to get made anyway.
What I actually had access to — and what that limits
GA4 and Search Console across all three properties. No server logs, no CDN data, nothing below GA4’s filtering layer. That’s worth saying plainly: when I say “ground truth” here, I mean the most verified number I had access to — not an absolute headcount. GA4 has its own blind spots. Consent mode gaps. Cookieless browsers. Server-side rendering that doesn’t fire tags cleanly. So the baseline I’m comparing against is itself an approximation — just a much better-documented one than either tool’s estimate.
What that means for how you read this: the findings are specific, not universal. Three sites, documented conditions, named limitations. Any comparison that doesn’t describe its ground truth methodology is making the same quiet move the tools make — dressing an estimate up as a fact. I’d rather tell you exactly how imperfect this test is than pretend it’s cleaner than it is.
The first pattern showed up immediately. And it wasn’t the one I expected.
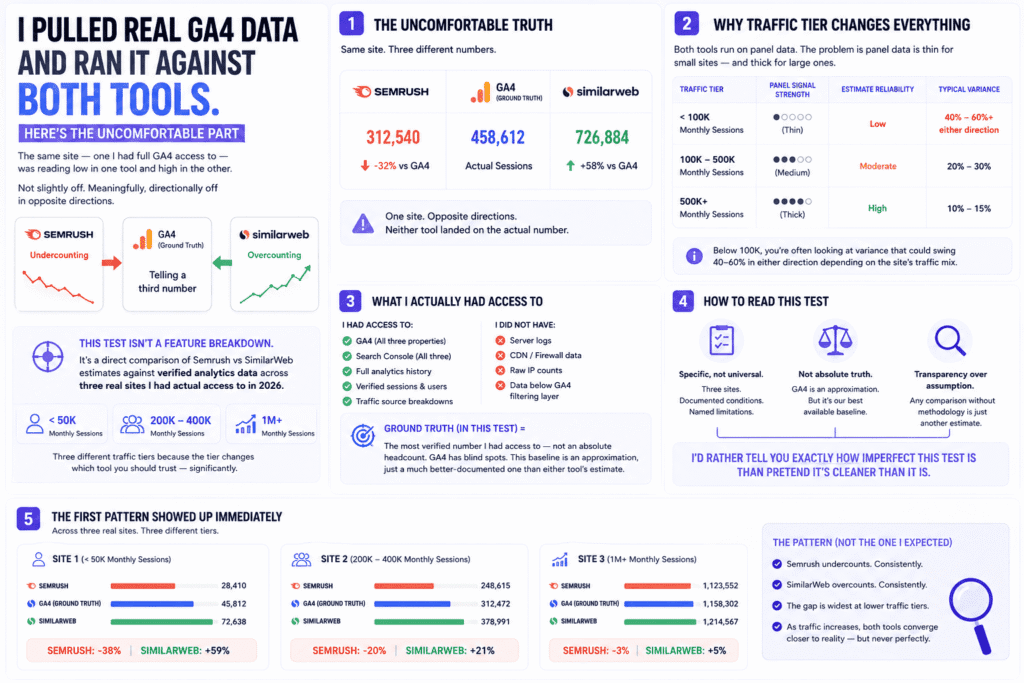
Related: Semrush vs SimilarWeb Accuracy Test: Which Tool Actually Gets Traffic Numbers Right?
Semrush Doesn’t Lie. It Just Has a Very Specific Blind Spot It Doesn’t Tell You About
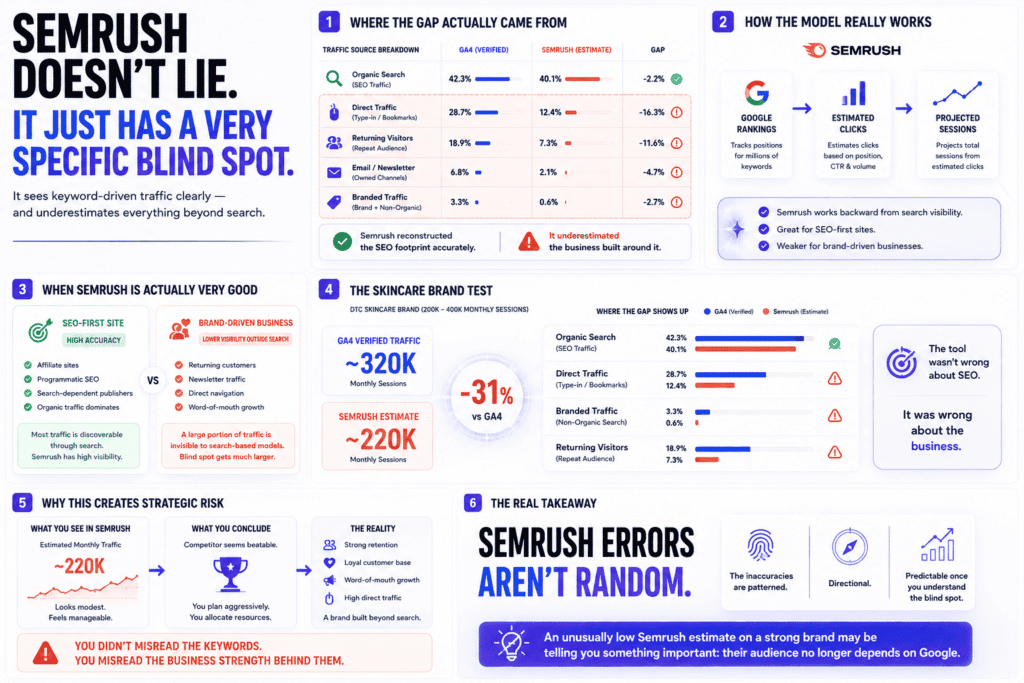
The 23% gap wasn’t spread evenly across channels. That’s what made it worth paying attention to.
On the highest-traffic site in the test — a property with real brand recognition and an audience that comes back on its own — Semrush’s organic estimate was actually pretty close to GA4. Within a few percentage points. The gap showed up almost entirely in direct traffic and returning visitors. Semrush hadn’t misread the site’s SEO footprint. It had just quietly ignored everything that didn’t look like a keyword click.
That’s not a bug. It’s how the model is built. Semrush reconstructs traffic by looking at what’s ranking and estimating how many clicks those rankings generate. It’s essentially working backward from search visibility to a session count. For a site that lives and dies by organic search — an affiliate build, a programmatic content play, a pure SEO asset — that method is genuinely good. The keyword fingerprint is almost the whole story, so the estimate holds up.
The problem is when you’re researching a competitor that has built something beyond search. A brand people type directly into the browser. A newsletter that drives 20% of sessions. A product people talk about and share without Google being involved at all. Semrush sees the organic layer clearly and the rest only dimly — and it doesn’t flag that distinction in the interface. The number just sits there looking authoritative.
I tested this against a DTC skincare brand in the 200–400K monthly session range. Strong retention, older customer base, significant direct traffic from people who’d been buying for years. Semrush’s estimate came in roughly 31% below GA4’s verified count — and when I broke down where the gap was, nearly all of it was in direct and branded traffic channels. Its estimate of their organic traffic was off by less than 8%. The tool wasn’t wrong about their SEO. It was wrong about their business.
This is the distinction that most Semrush vs SimilarWeb comparisons flatten when they call Semrush “inaccurate.” Inaccurate suggests random error — that you can’t predict which direction you’ll be wrong. That’s not what’s happening. Semrush’s errors are patterned and directional. Once you know the pattern, the estimate becomes more useful, not less, because you can read the gap as signal. A Semrush estimate that comes in unusually low for a well-known brand isn’t necessarily wrong about the keywords — it might be telling you the brand has built something that doesn’t depend on them.
Where Semrush accuracy genuinely breaks down — the situation where acting on the number gets someone into trouble — is competitive research on established consumer brands where direct traffic is a meaningful share of the mix. You pull the estimate, it reads modest, you conclude the competitor is beatable. Meanwhile they have a returning customer base, strong word-of-mouth, and retention metrics that no Semrush organic traffic estimate will ever surface. You’ve just made a strategic miscalculation because the tool’s blind spot happened to land on the competitor’s biggest asset.
The fix isn’t to distrust Semrush. It’s to know which sites to distrust it on — and to treat an unusually low estimate on a branded property not as the final answer but as a prompt to dig further.
SimilarWeb read higher on that same skincare brand. But closer to GA4 doesn’t mean what you think it means when you look at what it got wrong underneath the total.
SimilarWeb Looked More Accurate in My Test. I Don’t Entirely Trust That.
SimilarWeb’s total traffic number was closer to GA4 on two out of three sites. That should probably settle the accuracy question. It doesn’t.
On the skincare brand — the same property where Semrush came in 31% low — SimilarWeb landed within 9% of GA4’s verified session count. On the million-visit site it was within 11%, while Semrush was running about 18% low. If you stopped the test there, wrote up the results, and published them, you’d have a defensible article. SimilarWeb wins on total traffic estimation. Case closed.
Except I made the mistake of looking at the channel breakdown.
On that same skincare site, SimilarWeb attributed 41% of traffic to direct. GA4 showed 29%. It put 18% on social. GA4 showed 8%. The total estimate landed close to reality because the overcounts in some channels roughly cancelled out the undercounts in others — not because the underlying model was accurate. It found the right answer by making several wrong turns that happened to loop back. That’s not SimilarWeb accuracy. That’s a broken clock being right about the total while getting the time zones completely wrong.
This is where the real danger lives in the Semrush vs SimilarWeb debate — and why “which tool is more accurate” is a less useful question than it looks. Most people pulling competitor data aren’t just after a headline traffic number. They want to know how a competitor is growing. Paid or organic? Audience they’ve built or audience they’re renting? SimilarWeb’s channel attribution on mid-tier sites is where the confidence of the interface most dramatically outruns the reliability of the data — and the dashboard gives you absolutely no indication that this is happening. The channel breakdown sits right there next to the total, same visual weight, same clean percentages, zero signal that one number is far shakier than the other.
Pie charts don’t have error bars. They probably should.
The sub-50K site was its own kind of revealing. SimilarWeb estimated roughly 2.3x GA4’s actual session count. Semrush came in at about 60% of it. Same site, same month — the two tools didn’t even agree on which direction to be wrong. At that traffic level, both tools are essentially doing creative writing with thin panel data, and SimilarWeb traffic estimates for small sites deserve a level of skepticism the interface does nothing to encourage. The dashboards look identical whether the tool has real signal or almost none. That’s a design choice that benefits SimilarWeb more than it benefits you.
The underlying reason for this comes down to how each tool handles data scarcity differently. Semrush tends to show you less when it knows less — thin data on a small site often produces limited output or figures that visibly flag uncertainty. SimilarWeb fills the gap anyway. Panel data gets supplemented with ISP data, app usage signals, modeled estimates — and the result is a complete-looking report that carries the same interface confidence regardless of how much real signal is underneath it. A number that looks precise when it’s actually speculative is more dangerous than a number that looks approximate, because the precise-looking one doesn’t prompt you to go verify it.
So yes — SimilarWeb’s total traffic estimates were closer on the sites where total traffic is a meaningful metric. That result is real. It’s just not the whole story, and acting on it without looking at what’s happening underneath the total is exactly how competitive analysis goes wrong quietly.

Related: Semrush vs SimilarWeb: Stop Paying for Both Until You See This Breakdown
The Use Case Split Nobody In These Comparisons Will Actually Commit To
At some point every Semrush vs SimilarWeb comparison produces a two-column table. Semrush for SEO. SimilarWeb for market research. Sometimes there’s a row for “best for agencies” and a row for “best for enterprise.” The table looks like a conclusion. It’s actually the writer giving up.
Because the real split isn’t a table. It’s a question about what kind of wrong answer you can live with.
Semrush is built around a keyword-level view of the web. It reconstructs traffic by looking at search visibility and working backward. That makes it genuinely excellent at one category of question: anything that starts with “which keywords” or “what’s ranking” or “where is this competitor’s organic growth actually coming from.” The Semrush keyword research tooling held up across all three test sites — the database depth, the SERP feature data, the difficulty modeling. That’s not a talking point. It’s the one area where the tool’s methodology and the job to be done are cleanly aligned.
SimilarWeb is asking a different question entirely. It’s trying to model the whole traffic picture — search, direct, social, referral, paid — by pulling from panel data, ISP signals, and app usage patterns. That’s a market-level instrument, not a keyword-level one. When the job is understanding the relative size of five competitors in a category, tracking how a market segment’s traffic has shifted over 18 months, or figuring out whether paid search spend in a vertical is growing — SimilarWeb is the more appropriate tool. Not because it’s more accurate at the site level (the previous section showed it isn’t, not reliably), but because its model is at least trying to capture the full picture rather than just the search-visible slice of it.
The situation that causes the most actual damage — and I watched this happen inside a growth team at a mid-sized e-commerce company — is a single analyst running both jobs through one tool because the budget only covered one subscription. They were doing SimilarWeb market research for a category sizing exercise and getting channel breakdowns that looked authoritative. They were also trying to use SimilarWeb for keyword gap analysis and getting results that were thin enough to be nearly useless. Neither output flagged its own limitations. Both ended up in a deck. Decisions got made.
Semrush for agencies tends to work well precisely because agency work is keyword and content heavy — the core use case fits the tool. SimilarWeb for enterprise makes sense when the primary consumer of the data is a strategy or partnerships team that needs market-level signals, not a content team that needs to know what to write next. The mistake is letting procurement treat them as substitutes and pick the cheaper one, or the one the loudest person in the room already has a login for.
Both vendors have been quietly building into each other’s territory for years. Semrush added traffic analytics. SimilarWeb built out keyword tooling. Some of it is genuinely useful expansion. Most of it is feature parity theater — designed to neutralize the “we need both” conversation that keeps surfacing in software procurement reviews. The core competency gap hasn’t closed. A platform that originated as a competitive intelligence tool built around search data is a structurally different thing than one that originated as a web measurement platform — even when the feature lists look similar at the pricing tier you’re evaluating.
Using Semrush to do SimilarWeb’s job is like using a really good thermometer to check if it’s raining. Technically it’ll give you a number. The number just won’t answer your question.
What that gap costs — literally, in dollars, across the subscription tiers where most teams are actually making this decision — is where the comparison gets uncomfortable.

Related: Best SEO Tools for Small Businesses (Actually Worth Paying For)
What This Costs — And When the Price Gap Becomes a Real Argument
Nobody talks about how wide the gap actually is. So let’s just say it: SimilarWeb’s full feature set costs roughly 10 to 30 times what Semrush costs, depending on which tier you’re comparing and what a SimilarWeb enterprise rep decides your contract is worth. That’s not a pricing difference. That’s two tools that have priced themselves for fundamentally different buyers — and if you’re evaluating Semrush vs SimilarWeb as if they’re competing for the same budget line, you’re probably already looking at this wrong.
Semrush vs SimilarWeb pricing in 2026 — what you actually get at each tier
Semrush is priced like a practitioner tool. Pro runs around $117/month, Guru around $208, Business around $416. All three are self-serve — you can sign up, trial, decide, and cancel without talking to anyone. That matters. The ability to evaluate a tool without a sales cycle is itself a signal about who the product is built for.
The jump from Pro to Guru is where most serious users actually live. Pro hits its limits fast — 5 projects, 500 tracked keywords, no historical data beyond the current window. If you’re running SEO for more than one property or doing any kind of longitudinal competitive tracking, you’ll feel those walls within the first month. Guru removes most of them and adds content marketing tooling that’s more useful than it looks on the pricing page.
SimilarWeb’s pricing structure tells a different story. The Starter tier exists at around $125/month but it’s effectively a demo with a credit card attached — capped data history, limited results per metric, enough to orient yourself but not enough to do the category-level analysis that would justify the subscription. Past Starter, you’re in a sales conversation. The Team tier runs roughly $350/month for more generous limits. Beyond that, custom contracts — and the range I’ve seen quoted to agencies runs from $15,000 to $40,000 annually, depending on how many domains you’re tracking, how much history you need, and whether the rep has decided you’re price-sensitive.
That range should tell you something. When a vendor’s pricing spans that much territory, the number you get quoted has as much to do with your negotiating position as with what the product costs to deliver. Come in as a small agency asking about pricing and you’ll get a different number than a VP of Strategy at a Series C company who mentioned the tool in a procurement email. SimilarWeb is not a bad product. It is a product that has decided its value is whatever the market will bear in a given sales conversation.
So — is SimilarWeb worth it? For three specific situations, probably yes. Market sizing exercises where the traffic figure is going to an investor or a board and needs to look authoritative. Enterprise competitive intelligence programs tracking dozens of domains across multiple geographies. And — this is the uncomfortable one — agency reporting where the client is paying for a number that looks credible and is unlikely to cross-reference it against GA4. That last use case is real. It’s also not a reason to spend $30,000 on a tool. It’s a reason to have an honest conversation with your client about what competitive traffic estimates actually are.
Free versions compared: useful signal or loss leader with the good stuff gated
Semrush’s free tier gives you 10 searches a day. That’s enough to verify the tool is real and run a quick sanity check on a competitor’s organic visibility. It is not enough to do work. You’ll hit the limit mid-morning on your first serious research session and then you’ll make a decision about whether to upgrade. Which is exactly the experience Semrush designed.
SimilarWeb’s free version is more interesting — and more instructive about how the product thinks about itself. You can look up any domain without a credit card and see a traffic overview, top referrers, and a channel breakdown. The data is capped at 3 months of history and 5 results per metric, but the interface is fully functional. For a founder doing occasional spot-checks on major competitors, SimilarWeb free has genuine utility. You can get a directional read on a large, well-trafficked site without spending anything.
The catch — and it connects directly to what the test showed — is that the free tier shows you the same estimates that carry significant uncertainty below 500K monthly sessions. The confidence of the interface doesn’t change based on data quality. A domain with 30K monthly visitors gets the same clean dashboard treatment as one with 3 million. So the free tier can create a false sense of what the paid tier will deliver: the interface gets more generous, but the underlying signal on smaller sites doesn’t get meaningfully better just because you’re paying for it.
If the Semrush free trial is a door that opens into the paid product, SimilarWeb’s free tier is more like a window — you can see a lot through it, but what you’re seeing has the same structural limitations as what’s behind the paywall. Neither free tier will tell you that. You have to figure it out by running the numbers against something you can verify.
Which is, uncomfortably, exactly what most teams never do — and why the accuracy problem runs deeper than either tool’s methodology.

Related: Ahrefs vs Semrush vs Moz: The Complete & Honest SEO Tool Comparison
The Way Most Teams Use Both Tools Is the Real Accuracy Problem
The number leaves the tool accurate enough. What happens to it next is the problem.
An analyst pulls a competitor’s monthly traffic from whichever competitor analysis tool the team is paying for. It goes into a cell in a spreadsheet. Then someone — maybe the same analyst, maybe a strategist two weeks later — divides that number by an estimated revenue figure pulled from Crunchbase or a funding announcement or something a sales rep mentioned on a call. That derived figure becomes a conversion rate estimate. The conversion rate estimate becomes a benchmark. The benchmark goes into a board deck with two decimal places of false precision, and by the time it reaches the person making the budget call, the original traffic estimate has been compounded into a conclusion that carries none of the uncertainty of its inputs.
The tool didn’t do that. But the tool didn’t stop it either.
This is the accuracy problem that neither Semrush vs SimilarWeb comparisons nor either vendor’s marketing will ever surface — because it’s not a data quality problem, it’s a workflow problem, and workflow problems don’t get fixed by upgrading your subscription. Both tools are designed to make data accessible, visual, and easy to export. That’s genuinely useful. It’s also what makes the compounding problem invisible until it’s already caused damage. When a number lives inside a clean dashboard with a logo and a trend line, it stops feeling like a modeled estimate. It starts feeling like something that was looked up.
I’ve watched this specific sequence play out at three different companies — once at a DTC brand that built a six-month content roadmap off a competitor traffic estimate that was, as I later confirmed against GA4, off by nearly 40%. The roadmap wasn’t wrong because the analyst was careless. It was wrong because nobody in the process had a step that asked: is this number actually reliable enough to build on? That step doesn’t exist in most competitive intelligence workflows. It probably should be the first one.
The failure mode isn’t trusting a bad number. It’s trusting a number for a job it was never built to do. Traffic estimates are proxies for audience size. They are not proxies for revenue. They are not proxies for conversion rate. They are not market share figures in any precise sense. The moment a SimilarWeb or Semrush estimate becomes the denominator in a calculation, it’s doing load-bearing work it was never engineered to support — and the interface of neither tool will tell you that you’ve just crossed that line.
What makes this worse is that Semrush data accuracy and SimilarWeb data accuracy fail in opposite directions, as the test showed. Semrush undershoots established brands with strong direct traffic. SimilarWeb overshoots on totals while scrambling channel attribution. If your team runs competitive research through Semrush, your analysis is probably systematically underestimating the size of any competitor that has built real brand equity — the kind of competitor, ironically, that you most need to size correctly. If your team runs it through SimilarWeb, your category totals look plausible right up until someone asks where the traffic is actually coming from.
Neither failure announces itself. Both compound quietly as the estimates get reused, cited in later documents, and gradually promoted from “rough figure” to “what our data shows.”
The fix that actually works isn’t a better tool — it’s a verification pass before any traffic estimate gets used as an input to something else. Cross-reference large competitor figures against signals that don’t come from the same model: job posting velocity, app store ranking movement, ad spend indicators via tools like SpyFu or Pathmatics, press coverage frequency. Not to triangulate a precise number — you won’t get one — but to check whether the traffic estimation you’re working with is in the right order of magnitude before someone builds a strategy on top of it. It takes twenty minutes. The teams that do it consistently are almost always the ones who got burned by skipping it once.
The agency vs in-house version of this problem looks different enough that it’s worth treating separately — because the point at which an estimated number stops being questioned depends almost entirely on who’s in the room when it gets presented.

Related: How to Do a Complete SEO Audit for a Small Business Website: A Proven Step-by-Step Guide
Semrush vs SimilarWeb for Agencies vs In-House Teams: Different Tools for Different Leverage Points
Agencies don’t use these tools the way in-house teams do. The job is different, the audience for the output is different, and — this is the part that doesn’t get said enough — the standard for “accurate enough” is different.
In an agency, competitive data gets presented to a client who cannot verify it. That’s not an indictment of agencies — it’s just how the engagement works. When you walk into a pitch and tell a prospect their main competitor is pulling 1.8 million monthly visits with most of it coming from organic, the prospect is going to ask what that means for their strategy, not open GA4 to cross-reference your figure. The number needs to be credible in the room, not correct in the database. SimilarWeb’s interface is very good at producing numbers that look credible in rooms. The dashboards are polished, the channel breakdowns feel precise, and the visual presentation carries an authority that the underlying data doesn’t always deserve. For pitch work and executive reporting, that presentation layer matters — and pretending it doesn’t is its own kind of naivety.
For everything that happens after the pitch — the actual SEO agency tools work, the keyword research, the content gap analysis, the rank tracking, the monthly reporting — agencies run on Semrush. Not because it won a comparison test somewhere. Because it’s been built into the delivery workflow deeply enough that it’s essentially infrastructure now. The keyword data feeds the briefs. The position tracking feeds the reports. The client dashboards pull from Semrush exports. An agency that has been operating this way for two or three years has switching costs that have nothing to do with which tool is technically more accurate on traffic estimation.
In-house is structurally different and the difference matters more than most tool comparisons acknowledge. An in-house team is accountable for what the analysis produces downstream. If the competitive sizing was wrong and the content strategy built on it underperforms, that lands somewhere — in a performance review, in a budget conversation, in a post-mortem that someone has to write. Agencies can manage a bad number through a client relationship. In-house teams have to live with it.
That accountability changes the calculus. For an in-house SEO team doing content-driven work at a mid-market company, Semrush is the right daily instrument — the keyword research depth is genuinely useful, the site audit catches real issues, and the organic competitor tracking is accurate enough for the decisions it’s informing. When you have GA4 open in another tab, Semrush’s traffic estimation blind spots matter less because you’re using it primarily as a search visibility tool, not an audience sizing one.
The Semrush vs SimilarWeb question gets live for in-house teams the moment the research crosses from SEO into strategy. A growth team sizing a new market segment. A product team benchmarking competitors across geographies. A VP of Strategy building a category landscape for a board presentation. These are market-level questions, and handing someone a Semrush report in that context is handing them a keyword-level answer with the keyword part removed — what’s left is a traffic estimate that was never the tool’s primary output, presented as if it were. The VP won’t know that. The analyst who pulled the report probably does know it, and is hoping nobody asks too many questions about methodology.
Semrush for small business and solo practitioners is almost a different conversation entirely. At that scale, the question isn’t agency vs in-house — it’s whether the Pro tier gives you enough to justify the monthly cost against free or cheaper alternatives. It usually does, if keyword research and basic competitive tracking are genuinely part of the workflow. If someone is paying for Semrush primarily to check competitor traffic estimates, they’re using a $139/month keyword research platform as a traffic estimator — and there are cheaper ways to get numbers that are equally approximate.
SimilarWeb for agencies earns its place in exactly one consistent scenario: when the client is paying specifically for market intelligence that needs to hold up in a boardroom or an investor meeting. Category sizing. M&A due diligence. Competitive landscape work where the total traffic figure will be scrutinized by people who understand what they’re looking at. Outside that scenario, most agencies running SimilarWeb are paying enterprise pricing to produce pitch decks that Semrush would have served just as well at a fifth of the cost.
The teams that navigate this cleanly have usually made one explicit decision: which tool owns which question. Not “we use Semrush,” not “we use SimilarWeb” — but “Semrush answers keyword and content questions, and anything that needs a market-level traffic picture goes through a different process.” The teams that haven’t made that decision are running everything through whatever tool someone bought two years ago, inheriting its blind spots without knowing it.

Which One I’d Actually Pay For — And the Scenario Where I’d Pay for Both
Semrush. That’s the answer for most people reading this. Not because it won the accuracy test — it didn’t, not on total traffic figures — but because the thing it measures well is the thing most teams are actually measuring for.
Keyword gaps. Content opportunities. Organic rank movement. Where a competitor’s search visibility is growing and where it’s stalling. These aren’t exotic use cases — they’re the weekly work of most SEO and content teams, and Semrush does them better than anything else at its price point. The traffic estimation blind spots are real and this article has spent considerable space on them, but they’re blind spots I can navigate because I know which direction the errors run and on which site types they’re worst. Predictable error is a feature, not a consolation prize. SimilarWeb’s channel attribution problem is a different kind of wrong — quieter, more confident-looking, harder to catch before it’s already inside a decision.
So if someone asks me should I use Semrush or SimilarWeb and they’re an in-house SEO, a content strategist, a growth marketer doing competitive research as part of a broader job — the answer is Semrush, at the Guru tier if you’re tracking more than one property, Pro if you’re not. That’s Semrush worth it territory for almost any team where keyword and content work is happening regularly.
If neither tool feels right, the most credible Semrush alternative for keyword research and organic competitive analysis is Ahrefs — similar database depth, comparable pricing, a slightly different approach to difficulty modeling that some practitioners prefer. It won’t solve the traffic estimation problem because no tool in this category does. Ahrefs estimates too — it just estimates differently. But if Semrush’s interface or data freshness has frustrated you, Ahrefs is the only alternative worth serious evaluation at that price point. For traffic estimation specifically — the job SimilarWeb is built for — there is no strong SimilarWeb alternative at the self-serve tier. The closest competitors are either meaningfully worse on data coverage or significantly more expensive on enterprise contracts. The practical workaround most teams land on is combining Semrush’s traffic analytics with free-tier SimilarWeb spot checks and accepting the tradeoff consciously rather than by accident.
The scenario where I’d pay for both is specific enough that most teams will recognize whether it applies to them. You’re doing competitive analysis that will directly inform a capital allocation decision — a market entry call, a significant budget reallocation, an acquisition conversation — and the traffic figures in that analysis will be reviewed by someone who knows what they’re looking at and will push back if the numbers feel off. In that situation, SimilarWeb’s broader traffic picture sits alongside Semrush’s keyword-level detail in a way that’s genuinely additive. The places where the two tools disagree on the same site are often the most useful signal in the whole analysis — they’re pointing at something the model assumptions don’t agree on, which is usually worth investigating.
That situation comes up maybe three or four times a year for most teams. Paying for both as a standing subscription is the right answer for fewer organizations than the combined sales effort of both vendors would suggest. If you’re running both tools because a sales rep convinced you the overlap was value rather than redundancy, it’s worth auditing which one actually gets opened.
The Semrush vs SimilarWeb decision looks more consequential than it usually is. For the majority of in-house teams and small team SEO setups, the tool choice matters less than whether the team has built any discipline around treating estimated data as estimated. I watched a content team run a competitor’s Semrush traffic figure through eight months of strategy — content roadmap, resource allocation, channel prioritization — before anyone noticed the original estimate was off by nearly 40%. The tool wasn’t the problem. The absence of any step that asked how confident should we be in this, and what changes if it’s wrong, was the problem. That step doesn’t exist in most competitive intelligence workflows. It should probably be the first one.
For Semrush vs SimilarWeb for small teams specifically — where budget is tighter and one subscription has to do more jobs — the calculus is straightforward. Semrush’s Pro tier at ~$139/month gives you a genuinely deep keyword research tool, a site auditor, rank tracking, and traffic analytics that are accurate enough for the decisions a small team is actually making. SimilarWeb’s self-serve tiers give you traffic estimates with a data history limit and channel breakdowns that, as the test showed, carry real uncertainty below 500K monthly sessions. For a small team researching competitors who are mostly under that threshold — which is most competitive landscapes outside major consumer categories — SimilarWeb’s accuracy advantage at the total level doesn’t survive the channel breakdown.
Is SimilarWeb worth it? For enterprise competitive intelligence programs, investor-facing market sizing, and M&A research — yes, if the budget exists and the use case is real. For everything else, the free tier covers the occasional macro-level check on a large competitor, and the paid tiers are hard to justify unless someone is specifically being paid to produce market intelligence at scale.
Pay for Semrush. Use SimilarWeb free for spot checks on large, well-trafficked competitors where the total figure is reliable enough to be directional. And build the verification habit into your process — not because the tools are bad, but because the best SEO competitive analysis tool in the world still produces an estimate, and estimates don’t get better just because the dashboard looks confident.

Related: Keyword Research for New Websites: How to Find Keywords You Can Actually Rank For
Frequently Asked Questions : Semrush vs SimilarWeb
Is Semrush or SimilarWeb more accurate? Neither is unconditionally more accurate — the answer depends on site type and what you’re measuring. SimilarWeb’s total traffic estimates were closer to verified GA4 data in this test, landing within 9–11% on mid and high-traffic properties. But its channel-level attribution was significantly off on the same sites — overcounting direct and social traffic in ways that cancelled out at the total level but broke apart under scrutiny. Semrush was more consistently wrong on total traffic, undercounting established brands by 20–30%, but its organic traffic estimates were closer to ground truth on content-driven sites. If you need a total traffic figure, SimilarWeb is more reliable on sites above 500K monthly sessions. If you need keyword and organic channel data, Semrush is more reliable across all traffic tiers.
Which is better for SEO — Semrush or SimilarWeb? Semrush, without much qualification. SimilarWeb’s keyword data is thin, inconsistently updated, and lacks the SERP-level context that makes keyword research actionable. Semrush’s keyword database, position tracking, site audit tooling, and content gap analysis are the core of what most SEO practitioners use daily — and none of that has a meaningful equivalent in SimilarWeb’s feature set. SimilarWeb is not an SEO tool. It’s a market intelligence tool that happens to show some keyword data.
How does SimilarWeb get its data? SimilarWeb pulls from multiple sources — a panel of consented users whose browsing behavior is tracked, ISP-level data partnerships, app usage signals, and proprietary modeling to fill gaps where panel data is thin. The result is a broader traffic picture than Semrush’s keyword-reconstruction model, but one that carries significant uncertainty on smaller sites where the panel has limited coverage. Below 500K monthly sessions, SimilarWeb’s estimates are extrapolated more aggressively from thinner data — and the interface doesn’t signal when this is happening.
How does Semrush estimate website traffic? Semrush reconstructs traffic primarily from keyword data — it looks at what a site is ranking for, applies click-through rate models to those rankings, and works backward to a traffic estimate. This method is accurate for sites where organic search is the dominant acquisition channel but systematically undercounts direct traffic, dark social, and branded navigational visits that don’t leave a keyword fingerprint. Semrush’s traffic estimates are most reliable on content-heavy, SEO-driven sites and least reliable on established consumer brands with strong direct traffic habits.
Is SimilarWeb worth the price? For most in-house SEO and content teams — no. The self-serve tiers are limited enough that serious competitive research hits the walls quickly, and the enterprise pricing starts at roughly $1,500/month and scales significantly from there. The accuracy advantage SimilarWeb showed in this test on total traffic figures doesn’t justify that price gap for teams whose primary need is keyword research and organic competitive analysis. SimilarWeb earns its price tag in three specific situations: investor-facing market sizing, enterprise competitive intelligence programs tracking dozens of domains, and M&A due diligence where traffic figures need to hold up to serious scrutiny.
Can I use SimilarWeb for free? Yes — SimilarWeb’s free tier lets you look up any domain without a credit card and see a traffic overview, top referrers, and channel breakdown. The data is capped at three months of history and five results per metric. For occasional spot-checks on large, well-trafficked competitors, the free tier has genuine utility — particularly for getting a directional read on category leaders above 500K monthly sessions where SimilarWeb’s estimates are more reliable. For systematic competitive research across a portfolio of mid-sized competitors, the free tier’s limits surface quickly.
What is Semrush best used for? Keyword research, content gap analysis, organic competitor tracking, rank monitoring, and technical site auditing. These are the jobs Semrush was built for and where its methodology — keyword-reconstruction based, search-visibility focused — is genuinely well-suited to the task. Semrush is the right daily instrument for any team where SEO and content are primary growth channels. It is a less reliable tool for total traffic estimation on branded properties, market-level competitive sizing, or any analysis that needs to capture traffic sources beyond organic search.
Semrush vs SimilarWeb vs Ahrefs — which should I choose? Ahrefs and Semrush are closer competitors than either is to SimilarWeb. Both are keyword-research and organic-analysis tools built on similar methodology — Ahrefs has a stronger backlink index, Semrush has deeper workflow integration and a broader feature set at comparable pricing. If your primary need is keyword research and backlink analysis, Ahrefs vs Semrush is a genuine call worth making based on which interface fits your workflow. If your primary need is market-level traffic intelligence and competitive sizing, neither Ahrefs nor Semrush is the right tool — that’s SimilarWeb’s territory, at SimilarWeb’s price point.
Disclosure: Some links in this article maybe affiliate links. If you purchase through them I may earn a commission — at no additional cost to you. This article reflects genuine practitioner experience with the tools discussed. Affiliate relationships don’t influence the analysis, including where I’ve been critical.