Open Semrush and SimilarWeb on the same competitor domain right now. You’ll get two traffic numbers with no business being as far apart as they are — and if you’ve ever stared at that gap and quietly wondered which one to trust, you’re not alone. Most people pick the number that fits the story they’re already telling. That’s not analysis. That’s confirmation bias with a professional interface.
Most articles about Semrush vs SimilarWeb don’t help. They compare pricing tiers, count features, and declare a winner — without ever testing the one thing both tools are actually sold on: whether their traffic estimates are close enough to reality to act on. That’s the only question that matters, and it’s the one this article is built around.
The answer isn’t clean. Neither tool is universally more accurate. Accuracy depends on the type of site you’re measuring, the channels that drive its traffic, the markets it operates in, and the stakes of the decision you’re making. Get the tool-to-job match wrong and you won’t know you’re wrong — the interface will keep producing confident-looking numbers either way.
This article tests both tools against those conditions. No feature tables. No affiliate-driven verdicts. Just a clear-eyed look at where each tool holds up, where it quietly falls apart, and how to stop making decisions on data you haven’t actually pressure-tested.
Table of Contents
Quick Verdict: Which Tool Should You Use?
Before the full breakdown — here’s the short version for readers who need a fast answer. The nuance is in the sections below, but this table covers most decisions.
| Your situation | Best tool | Why |
|---|---|---|
| Daily SEO work — keyword research, rank tracking, content strategy | Semrush | Built for search. Larger keyword database, sharper organic estimates, fully transparent pricing from $117/mo |
| Strategic competitive intelligence — channel mix, market benchmarking, acquisition analysis | SimilarWeb | Sees the full traffic picture across all channels, stronger for non-organic and international data |
| Researching small or niche competitors (under 100K monthly visits) | Neither alone | Both tools are structurally unreliable at this scale — treat estimates as directional signals only |
| Analyzing competitors in international markets outside US/UK | SimilarWeb | Stronger panel representation in Europe, Asia, and emerging markets where Semrush thins out |
| Making financial decisions — valuations, ad deals, budget allocation | Triangulate both | A 40% margin of error compounds through financial models — single-tool estimates aren’t sufficient |
| Ecommerce needing Amazon and YouTube keyword data | SimilarWeb | Only tool that covers keyword demand across Google, Amazon, and YouTube in one view |
| Solo practitioner or small team on a budget | Semrush | Transparent pricing, full SEO toolset from entry level, 14-day free trial with no usage caps |
| Enterprise org with multiple teams needing shared intelligence | SimilarWeb | Cost justifies at organizational scale when marketing, product, sales, and strategy all draw from the same platform |
The honest summary: neither tool is universally better. Semrush wins on SEO execution, keyword depth, and price transparency. SimilarWeb wins on channel breadth, international coverage, and strategic intelligence. The question isn’t which tool is right — it’s which tool is right for what you’re actually trying to do.
The Numbers Don’t Match. That’s the Whole Problem
Pull up the same competitor domain in Semrush and SimilarWeb on the same day and you’ll get two numbers that have no business being that far apart. Not a rounding difference. Not a timezone issue. One tool might show 200,000 monthly visits. The other shows 800,000. Same domain. Same month. Completely different reality.
Most marketers see this gap, feel briefly unsettled, and then do one of two things: they pick the number that supports the narrative they’re already building, or they average the two and pretend that’s a methodology. Neither is analysis. Both are ways of making a decision on a number you’ve essentially invented yourself.
The thing is — the discrepancy isn’t a bug. It’s not a sign that one tool is broken or that the other is lying. Semrush and SimilarWeb are not measuring the same thing in the same way, and expecting them to produce the same output is like expecting two doctors to give you the same diagnosis when one is reading a blood test and the other is reading an X-ray. The inputs are different. Of course the outputs are too.
But here’s where the Semrush vs SimilarWeb debate gets stuck: most people never ask why the numbers differ. They jump straight to which number to trust, which tool to prefer, which review article to believe — without ever examining what each tool is actually counting and under what conditions that counting falls apart. That prior question is the one this article is built around, because the answer is what determines which tool you should be using for your specific situation — and in some cases, whether you should be trusting either of them at all.
The stakes here aren’t small. Bad traffic data doesn’t stay contained to a dashboard. A wrong estimate in month one becomes a wrong content hypothesis in month two, a misallocated budget by Q3, and a post-mortem conversation by Q4 where nobody can quite explain why the strategy underperformed. Traffic numbers from these tools get used to negotiate ad partnerships, justify acquisition prices, benchmark PPC spend against competitors, and build content strategies from the ground up. When the number is off by 40% — and it often is — every decision downstream is quietly compromised.
The feature comparisons and pricing breakdowns can wait. Before any of that matters, you need to know whether the number either tool gives you is close enough to reality to act on. That’s the only question worth starting with.

Before You Compare Outputs, Understand What Each Tool Is Actually Counting
Here’s something Semrush doesn’t make obvious in its main interface: the traffic number you see in Domain Overview isn’t based on actual traffic at all. It’s based on keyword rankings. Semrush takes the keywords a site ranks for, multiplies search volume by the average CTR at that position, and calls the result an estimated visit count. That’s a projection — a model of what traffic should look like given search visibility. It’s useful, but it has a hard ceiling: the moment a site gets meaningful visits from direct, social, referral, or email, those channels have no keyword ranking to anchor them to, so they largely disappear from the estimate. Semrush does have a separate Traffic Analytics tool that pulls clickstream data across all channels — but that’s a paid add-on inside the .Trends toolkit, not included in the standard plan most people are actually using when they run a comparison.
SimilarWeb starts from the opposite end. It combines first-party analytics data from millions of partner websites, anonymous behavioral signals from its own browser products installed on devices worldwide, ISP-level data agreements, and public web crawling — all fed into a single composite model. Its device panel reportedly covers over 100 million unique devices globally, with stronger representation in European and Asian markets than Semrush. The goal was never to answer SEO questions. It was to answer market questions — how does a business acquire customers online, across every channel, not just search. That’s why SimilarWeb’s numbers tend to run higher. It’s not inflating — it’s counting more things.
So when you run the Semrush vs SimilarWeb comparison on the same domain and get two different numbers, you’re not watching one tool be right and the other be wrong. You’re watching two different questions get answered. Semrush is telling you what search sends. SimilarWeb is telling you what everything sends. For a site that lives and dies by organic — an affiliate blog, a content-led SaaS, a review site — those answers will be reasonably close. For a heavily branded consumer product, a news publisher, or any site with a strong direct traffic base, they’ll be far apart in ways that have nothing to do with accuracy and everything to do with scope.
The part that doesn’t get said enough: both tools share a unit — monthly visits — but they don’t share a definition of what counts toward that unit. One was an SEO tool that learned to estimate total traffic. The other was a market intelligence tool that learned to do SEO. Expecting them to produce the same number is a category error, not a data problem. You could make either tool look “wrong” simply by choosing a site that plays to the other tool’s strengths.
That’s the methodological gap. Now here’s where it gets worse — because both models fall apart in the same situation, just for different reasons, and that situation describes the majority of sites most marketers are actually trying to research.

Small Sites Make Both Tools Look Foolish
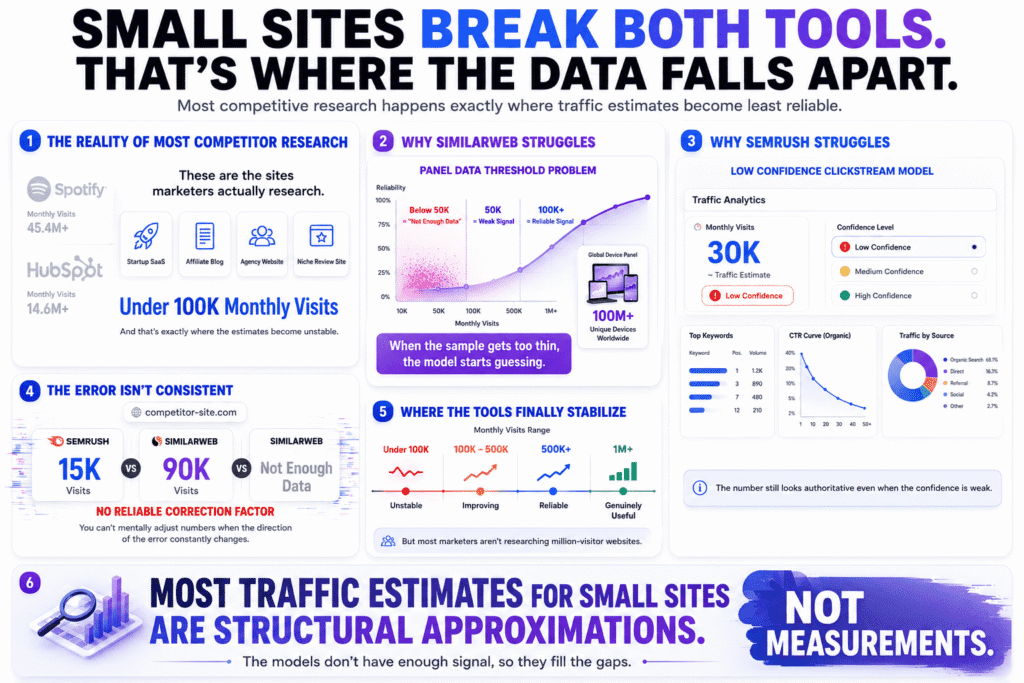
The sites most marketers are actually trying to research aren’t Spotify or HubSpot. They’re the mid-sized competitor quietly climbing the rankings, the agency you keep losing pitches to, the SaaS tool that launched eight months ago and somehow keeps showing up everywhere. Those sites — the ones that actually matter in daily competitive work — are almost always under 100,000 monthly visits. And that’s exactly where both tools are least reliable.
The most rigorous independent test of this comes from a SparkToro study that compared Semrush, SimilarWeb, Ahrefs, and Datos against real Google Analytics data across 641 sites. Semrush scored highest on correlation with actual traffic at 0.790 out of 1.0, while SimilarWeb came in at 0.659 — a meaningful gap, but neither close to perfect. Before that result gets used to declare Semrush the winner, two things are worth knowing: first, the study compared Semrush’s Domain Analytics — its organic-only projection model — against SimilarWeb’s total traffic estimates, which isn’t a like-for-like comparison. Second, SparkToro worked closely with SimilarWeb during the study’s construction, which raises legitimate questions about neutrality that the original article doesn’t fully address. The study is still the best independent benchmark available — but cite it knowing what it measured and what it didn’t.
SimilarWeb’s accuracy for small websites under 50,000 to 100,000 monthly visits is poor — the panel model requires a minimum threshold of observed users before it can generate reliable extrapolations. Below that line there aren’t enough data points to model against, so what you’re looking at isn’t an estimate — it’s a generated approximation of what a site that size probably looks like, based on other sites the model has seen. When the data gets too thin, SimilarWeb just shows “Not enough data” — which is at least honest. The problem is everything it does show just above that threshold, where the numbers look confident but the underlying sample is barely there.
Semrush handles this more quietly. Its Traffic Analytics module includes an accuracy indicator — a low/medium/high confidence rating based on available clickstream data — that most people scroll straight past. On a competitor doing 30,000 monthly visits, that indicator is almost always low. For sites with little traffic, both services demonstrated large inaccuracies — and the smaller the website, the less accurate the approximations. The number on screen doesn’t change to reflect that. It just sits there looking authoritative.
What makes this genuinely difficult in the Semrush vs SimilarWeb context is that the error isn’t consistent enough to correct for. It’s not a reliable 20% undercount you could mentally adjust. A site doing 40,000 monthly visits might show as 15,000 in one tool and 90,000 in the other — or appear as “not enough data” in SimilarWeb while Semrush reports a number with false confidence in the opposite direction. There’s no way to know which way the error runs without access to the site’s actual analytics. You can’t even tell you’re wrong.
SimilarWeb’s accuracy sweet spot sits between 5,000 and 100,000 monthly visitors — and the lower half of that range is unreliable enough to treat with real caution. Above 500,000 visits both tools stabilize. Above a million they’re genuinely useful. But that describes a tiny fraction of the web and an even tinier fraction of the competitive sets most marketers are actually working with.
The thing nobody says plainly: most competitive research in this industry is being done on sites small enough that the traffic numbers aren’t imprecise — they’re invented. Not maliciously. Just structurally. The models don’t have enough signal so they fill the gap, and the interface presents the result with the same visual confidence it uses for sites ten times the size. If you’ve ever built a content strategy around a competitor’s traffic estimate and had it dramatically underperform, this is a plausible explanation that doesn’t require anyone to have made a mistake.
Which raises the question of what happens when the sites are large enough for the data to hold — because that’s where the tools genuinely diverge, and not in the direction most people expect.
Semrush Wins on Organic. SimilarWeb Sees More of Everything Else
Once you’re past the small-site noise floor, the tools do genuinely different things well — and the split is more specific than most comparisons admit.
Semrush is more accurate for organic search and keyword-driven traffic. SimilarWeb is more accurate for large sites and multi-channel breakdown. That sounds like a diplomatic draw, but it isn’t. It means each tool is reliable for a different layer of the same question, and if you use one to answer what the other was built for, the data will quietly mislead you without flagging that it’s doing so.
Semrush’s organic estimates are sharper because organic is what it was built around. Every other data type — direct, referral, social — gets estimated against a model that was fundamentally designed for search. Semrush’s estimates for direct and referral traffic can be off by 50 to 70%. Not occasionally. Structurally. Which means if you’re using Semrush to understand how a competitor acquires customers beyond search, you’re looking at numbers that might as well be placeholders. The tool was never really designed to answer that question, and the interface doesn’t tell you that.
SimilarWeb’s channel breakdown is where it earns its cost. The full split across direct, organic, paid, social, referral, and email is genuinely more reliable than what Semrush produces for those same channels — because SimilarWeb was built to see all of them, not just infer them from search signals. A competitor that looks like a pure SEO play in Semrush might show up in SimilarWeb as heavily direct-traffic dependent. That’s not a data discrepancy — that’s a brand signal Semrush’s architecture structurally cannot see. Miss it and you’ve misread the competitive landscape in a way that affects how you’d prioritize your own acquisition strategy.
Here’s the thing that rarely gets said about the Semrush vs SimilarWeb accuracy split: Semrush makes fewer mistakes overall, but the mistakes it makes tend to be massive. SimilarWeb’s errors are more distributed — spread across channels, slightly off in multiple directions, but rarely catastrophically wrong in a single place. Semrush can be extremely accurate for nine sites in a competitive set and completely wrong about the tenth, with nothing in the interface to tell you which one it got wrong. For anyone building a cross-domain comparison, a randomly distributed catastrophic outlier is a harder problem than consistent moderate inaccuracy — because at least with consistent inaccuracy you know to apply a mental adjustment. With Semrush’s error pattern, you don’t know where the landmine is until you step on it.
The practical upshot: if your workflow is primarily SEO — ranking analysis, content gap work, organic share of voice — Semrush is the right primary tool and SimilarWeb is a useful cross-check. If your workflow is strategic — channel mix, acquisition modeling, how a competitor’s business actually grows — SimilarWeb is where you start and Semrush fills in the keyword detail. Using either one alone for strategic decisions means accepting blind spots you probably haven’t mapped.
What neither tool discloses prominently is that this accuracy picture changes the moment the sites you’re analyzing are outside North America — and it changes in a direction that will surprise most Semrush-first users.

Related: Ahrefs vs Semrush vs Moz: The Complete & Honest SEO Tool Comparison — If you’re weighing all three major SEO tools before committing, this breakdown covers how Ahrefs and Moz stack up against Semrush across the same workflows.
Semrush Has a Geography Problem It Doesn’t Advertise
Semrush will tell you it covers 190 countries. That’s technically true. What it won’t tell you is that coverage and accuracy are not the same thing — and the gap between them widens considerably the moment you leave North America and Western Europe.
For sites with significant international traffic, SimilarWeb outperforms Semrush due to its stronger panel representation outside North America. Semrush still shows weaker representation in Southeast Asia, the Middle East, and parts of Latin America. The insidious part isn’t the gap itself — it’s that the interface doesn’t show it. Pull up a competitor based in Jakarta or Riyadh and Semrush returns a number in the same format, with the same visual confidence, as it would for a site based in Chicago. No warning label. No accuracy indicator flagging that the underlying panel is thin. Just a number that looks like all the other numbers.
Semrush’s clickstream panel was built when its user base was overwhelmingly North American and Western European — panel composition follows product adoption, not global internet demographics. SimilarWeb made deliberate moves to expand internationally, particularly through ISP-level data partnerships in Asia and Europe that give it ground-level coverage Semrush’s browser-extension-dependent model can’t easily replicate. SimilarWeb’s consumer panel covers over 100 million unique devices globally, with stronger representation in European and Asian markets. That gap isn’t marketing spin — it’s the direct result of how each company built its data infrastructure over the last decade, and it doesn’t close just because Semrush added more countries to a dropdown menu.
For purely domestic analysis in the US or UK, this is invisible. The panels are dense enough that both tools produce usable estimates. But ask Semrush to estimate traffic for a Southeast Asian ecommerce player, a Middle Eastern news publisher, or a Brazilian SaaS company and you’re asking it to work in markets where it’s extrapolating more than it’s measuring. The model fills the gap with inference. The interface presents the result as data.
This is the part of the Semrush vs SimilarWeb picture that most comparison articles miss entirely — partly because they’re written by and for North American marketers who never bump into the problem. If your competitive set is genuinely global, or you’re expanding into markets outside the US and Europe, brand recognition won’t compensate for panel density. Semrush being the more widely used platform doesn’t make its Indonesian traffic estimates more accurate. It just makes more people confident in numbers they shouldn’t be.
Which is a manageable problem when the stakes are a content calendar. It becomes a different category of problem when the number is going into a pitch deck, a valuation model, or a budget justification.

This Stops Being an SEO Debate the Moment Money Is Involved
Traffic data stops being an SEO metric the moment it lands in a spreadsheet that someone else is going to act on financially. That happens more often than either tool’s marketing would suggest.
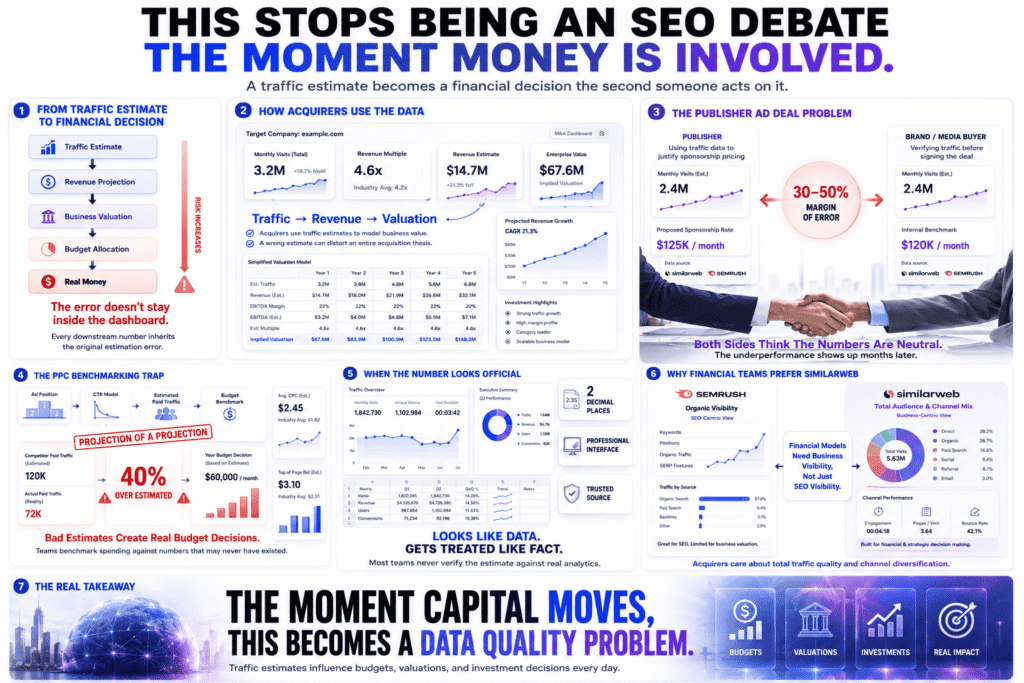
Acquirers use SimilarWeb data to build financial models that estimate how much a target company makes, what it might be worth, and how much value can be created by growing it. That’s not a hypothetical use case — that’s the actual workflow serial acquirers describe in public. A traffic estimate feeds a revenue multiple, which feeds a valuation, which feeds a wire transfer. The margin of error doesn’t stay in the dashboard. It travels downstream into every number built on top of it.
Publisher ad deals work exactly the same way. A media company negotiating a sponsorship uses its own traffic figures — often pulled from SimilarWeb or Semrush because third-party numbers look more neutral than self-reported ones — to justify its rate card. The brand’s media buyer uses the same tools to verify before signing. When both sides are working from estimates with a 30–50% margin of error, neither party actually knows what they’re agreeing to. The deal closes anyway, and the gap surfaces six months later as underperformance that everyone attributes to seasonality.
PPC benchmarking is where the Semrush vs SimilarWeb accuracy gap bites hardest and most quietly. Semrush’s paid traffic numbers are calculated using average click-through rates and positioning in the top eight paid positions — not actual spend data. It’s a model of what a competitor’s paid traffic should cost given their search visibility, not what they’re actually spending. A team that uses this to benchmark their own paid budget against a competitor’s is calibrating against a projection of a projection. If Semrush overestimates a competitor’s paid traffic by 40%, the natural conclusion is that you’re underinvesting — and budgets get adjusted accordingly. That’s a direct dollar consequence that traces back to an estimate nobody verified and a methodology the interface doesn’t explain.
The people making these decisions usually have no particular reason to question the number. It comes from a credible tool with a professional interface. It has two decimal places. The person pulling it wasn’t the one who chose the tool, and almost certainly wasn’t the one who ever benchmarked its accuracy against real data. They see a figure and treat it as a fact — which is exactly how a 40% estimation error becomes a budget decision becomes a post-mortem question nobody can cleanly answer.
Hedge funds and institutional investors actively use SimilarWeb traffic data as an input into investment models — not as a rough directional signal, but as a data point that moves capital. At that level, asking which tool is more accurate isn’t an SEO conversation. It’s a data quality question with fiduciary weight. The fact that most people discuss these tools in marketing contexts doesn’t change how the numbers get used once they leave the marketing team.
What’s interesting is that the financial use cases almost uniformly favor SimilarWeb — not because it’s more accurate in absolute terms, but because its multi-channel view maps more cleanly onto how a business actually generates revenue. An acquirer doesn’t care about organic share of voice. They care about total addressable traffic, engagement quality, and channel diversification. Semrush’s organic-first architecture answers a different question than the one financial due diligence is actually asking.
Keyword Research: The Feature Gap Nobody Prices Into the Decision
Most people comparing these two tools obsess over the traffic accuracy question and barely glance at the keyword research gap. That’s backwards. For the majority of SEOs, keyword research is what they open the tool for every single day. Traffic estimates get checked occasionally. Keyword data gets used constantly. The feature asymmetry here is the one that actually determines whether the tool fits your workflow — and it’s the one that gets the least serious treatment in most comparisons.
Semrush’s keyword database contains over 26 billion keywords, significantly outpacing SimilarWeb’s 5 billion. But the raw number matters less than what each tool does with its data. In Semrush you can filter by difficulty, intent, SERP features, question format, and competitive density — and get keyword suggestions branching into thousands of long-tail variations from a single seed term. The Keyword Magic Tool alone covers more ground than SimilarWeb’s entire keyword offering. SimilarWeb’s keyword overview lacks SERP analysis and competitor keyword breakdowns — both of which are standard requirements for any functional keyword research workflow. It shows you which keywords drive traffic to a domain. It doesn’t help you build a content strategy from them. Those are different jobs, and SimilarWeb only does the first one.
Here’s the capability that ecommerce teams consistently undervalue until they actually see it: SimilarWeb provides keyword data for Amazon and YouTube in addition to Google. For a brand doing meaningful volume on Amazon, or a business where YouTube search drives product discovery, that’s not a footnote — it’s visibility into buying intent that Google-only keyword tools structurally cannot see. Most Semrush vs SimilarWeb comparisons either miss this entirely or treat it as a curiosity. For the right business it resolves the entire comparison on its own.
If you’re an SEO whose primary job is ranking content in Google, SimilarWeb’s keyword tools are not a functional substitute for Semrush. The database is smaller, the filtering is thinner, the workflow support is minimal. You’d feel the absence on day one. If you’re an ecommerce strategist who needs to understand search demand across Google, Amazon, and YouTube in one view, Semrush doesn’t cover what you actually need — and no amount of organic keyword data fills that gap. Semrush offers much larger databases, more advanced filtering, better country-level data, and clearer difficulty metrics including estimates of how many backlinks you’d need to rank. For SEO execution, it isn’t close. But execution and intelligence are different jobs, and the tool that’s better at one isn’t automatically better at the other.
There’s one more capability gap in this section that didn’t exist two years ago and now changes the comparison meaningfully for anyone thinking about search visibility beyond Google’s traditional blue links. Semrush now lets you monitor how often your domain is cited or referenced inside AI-generated answers — currently supporting ChatGPT, Google AI Overviews, and Google AI Mode. That’s not a minor feature addition. In 2026, a growing share of search journeys end inside an AI-generated answer without a click ever happening. If you don’t know whether your content is appearing in those answers — or whether your competitor’s is — you’re flying blind on an increasingly significant slice of search visibility.
SimilarWeb has an AI visibility offering too, but it’s locked behind enterprise pricing — unavailable on any self-serve plan, accessible only through a custom contract. For the vast majority of practitioners comparing these tools, SimilarWeb’s AI search intelligence simply isn’t in the conversation. Semrush’s equivalent is available on standard plans, which means an SEO paying $117 per month has access to AI citation tracking that a SimilarWeb customer on a $400 per month plan doesn’t.
This is where the Semrush vs SimilarWeb feature gap becomes most asymmetric in 2026. SimilarWeb built its advantage on total traffic visibility across all channels — but AI search is a channel it can’t yet serve at accessible price points. Semrush, coming from a search-first architecture, extended naturally into AI search monitoring in a way that maps directly onto existing SEO workflows. For any practitioner whose clients or stakeholders are starting to ask about AI search visibility — and by mid-2026, most are — this gap alone may resolve the comparison before the pricing conversation even begins.
Paying for SimilarWeb’s enterprise tier to do keyword research is like hiring a strategist to write your meta descriptions. Technically possible. Structurally wrong. And expensive in a way that compounds — because the price gap between these tools is larger than most people realize before they’ve already committed to one.

Related: Keyword Research for New Websites — Semrush wins on keyword depth. Here’s how to put that advantage to work if you’re building a keyword strategy from scratch.
The Price Gap Is Bigger Than It Looks, and It Widens Fast
The entry-level numbers look closer than they are. Semrush’s SEO Classic Pro starts at $117/month billed annually — keyword research, competitor analysis, backlinks, site audit, position tracking, all included. SimilarWeb’s equivalent self-serve plan for individuals sits around $125/month, but it covers traffic analysis only. The moment you need keyword research, rank tracking, or backlink analytics, you’re no longer comparing self-serve plans. You’re calling SimilarWeb’s sales team.
That’s not a minor inconvenience. SimilarWeb has quietly moved most of its meaningful plans behind a “contact sales” wall. Team, Business, and Enterprise tiers are all custom-priced, contract-based, and require a sales process to access. There’s no public price to compare against. You find out what it costs after a demo, a discovery call, and a proposal — which means by the time you have a number, you’ve already invested time in the relationship and anchoring has done its work.
Semrush’s pricing, by contrast, is fully public and tiered cleanly. The Guru plan at $208/month adds historical data, multi-location tracking, and content tools. The Business plan at $416/month adds Share of Voice, API access, and extended limits. If you specifically need the traffic intelligence layer that competes most directly with SimilarWeb, Semrush’s Traffic & Market add-on runs $289/month on top — giving you competitor traffic overview, market trends, and regional data. That’s a meaningful additional cost, but it’s a published number you can budget against before committing.
The free trial asymmetry matters here too. Semrush offers a genuine 14-day trial of its full toolset. SimilarWeb offers 7 days with usage caps tight enough that a single afternoon of serious research can exhaust them. You can make an informed decision about Semrush before paying. With SimilarWeb’s business plans, the pricing conversation happens before the product evaluation in any meaningful depth.
The Semrush vs SimilarWeb pricing decision ultimately splits along a clean organizational line. Semrush is priced for individuals, small teams, and agencies who want transparent, scalable access to SEO and competitive data. SimilarWeb is priced for organizations large enough to have a procurement process — where the sales conversation, the custom contract, and the annual commitment are normal parts of how software gets bought. Neither model is wrong. But if you’re a solo practitioner or a team of five trying to evaluate both tools on a budget before committing, Semrush gives you that path. SimilarWeb increasingly doesn’t.
The opaque pricing isn’t an accident. It reflects who SimilarWeb is actually selling to — and if that buyer isn’t you, the comparison effectively ends here.

Related: Best SEO Tools for Small Businesses (Actually Worth Paying For) — If neither Semrush nor SimilarWeb fits your budget or workflow, this roundup covers the alternatives worth paying for at every price point.
Frequently Asked Questions
Is Semrush more accurate than SimilarWeb? Neither tool is universally more accurate. Semrush is more accurate for organic search and keyword-driven traffic estimates. SimilarWeb is more accurate for total traffic across all channels, particularly for large sites and international markets. Accuracy depends entirely on what type of site you’re measuring and which traffic channels matter most for your decision.
Why do Semrush and SimilarWeb show different traffic numbers for the same site? Because they measure different things. Semrush’s core model is built around keyword rankings and search visibility — it estimates traffic by modeling what a site’s search positions should deliver. SimilarWeb combines clickstream data, ISP partnerships, browser panel data, and direct measurement across all channels. Different inputs produce different outputs — the gap isn’t a bug, it’s a methodology difference.
Which tool is better for competitor research? It depends on what you’re trying to learn. Semrush is better for understanding a competitor’s organic keyword strategy, content gaps, and search-driven growth. SimilarWeb is better for understanding how a competitor acquires customers across all channels — direct, paid, social, referral, and email. For most SEO workflows, Semrush. For strategic competitive intelligence, SimilarWeb.
Can I use Semrush and SimilarWeb together? Yes — and for high-stakes decisions, you should. Using both tools and comparing outputs is the most reliable way to triangulate toward a defensible estimate. Where both tools agree directionally, the signal is stronger. Where they diverge significantly, that divergence itself is useful information — it usually means the site has a meaningful non-organic traffic source that Semrush’s model can’t see.
Is SimilarWeb accurate for small websites? No — and neither is Semrush. Both tools are unreliable for sites under roughly 50,000–100,000 monthly visits. SimilarWeb won’t show data at all for sites under 5,000 monthly desktop visits. Below the 100,000 threshold, treat any estimates from either tool as directional signals at best, not figures you’d put in a strategy document.
Is Semrush or SimilarWeb better for agencies? Semrush is the more practical choice for most agencies. Its pricing is transparent, its keyword and SEO toolset covers the core of most agency workflows, and its plans scale without requiring a sales conversation. SimilarWeb becomes worth the investment for agencies doing enterprise-level strategic work for large clients — where the multi-channel intelligence and market benchmarking justify the cost and the contract-based pricing model.
Do I need both Semrush and SimilarWeb? Most practitioners don’t. If your primary work is SEO execution — keyword research, content strategy, rank tracking, technical audits — Semrush covers everything you need. If your work is primarily strategic intelligence — market sizing, channel benchmarking, acquisition modeling — SimilarWeb is the more appropriate tool. The case for both arises when you’re doing high-stakes financial or strategic decisions where triangulating traffic estimates from two methodologies reduces your margin of error.
Related: How to Do a Complete SEO Audit for a Small Business Website: A Proven Step-by-Step Guide — Once you’ve chosen Semrush, this guide shows exactly how to put its site audit tools to work for client and small business websites.
Neither Tool Is Right. Here’s How to Stop Pretending One Is
The question was never which tool is right. It was always which tool is wrong in a way you can live with.
Both Semrush and SimilarWeb are estimation engines working from incomplete data, extrapolating from panels that cover a fraction of actual internet behavior, applying models built on historical patterns to predict current reality. The margin of error isn’t a bug that will get patched in the next release. It’s structural. It’s the ceiling of what third-party traffic estimation can do without access to a site’s actual analytics — and neither tool is close to that ceiling for most of the sites most people actually research.
What changes between them isn’t accuracy in the abstract. It’s where the error concentrates and what it costs when it shows up. Semrush’s errors cluster in non-organic channels and non-English markets. SimilarWeb’s errors cluster in small sites and granular keyword data. Those aren’t equivalent failure modes — one matters more depending entirely on what you’re trying to do.
The most honest framework for the Semrush vs SimilarWeb comparison isn’t a feature table or a price breakdown. It’s one question: what decision are you making, and what does it cost you if the traffic number is 40% off? For content strategy — topic prioritization, competitor page analysis, keyword opportunity assessment — a 40% error is workable. You’re making directional calls, not precise ones, and both tools are directionally useful above the small-site threshold. For budget allocation, partnership pricing, or acquisition due diligence, 40% off isn’t workable. It compounds through every downstream calculation. At that point, neither tool should be your primary source. You triangulate both against first-party data, or you accept you’re operating on informed guesswork and price that risk into the decision.
The mistake most teams make isn’t choosing the wrong tool — it’s using one tool for both jobs. Running keyword research and strategic competitive intelligence through the same platform because paying for two feels redundant. The result is one job done well and one done with data that was never designed to answer it. The budget that feels like an inefficiency is often the cost of actually getting the question right.
Traffic numbers from both tools should be treated as relative indicators, not absolute counts. The value isn’t in the specific figure — it’s in the direction of change over time, the relative gap between competitors, channel mix as proportion rather than volume. A site showing 400,000 monthly visits might actually get 300,000 or 600,000. What either tool can reliably tell you is whether that site is growing or declining, whether it over-indexes on organic relative to competitors, whether a channel shift happened between quarters. That’s a narrower claim than either tool’s marketing makes — but it’s the one that holds up. Build your workflows around what the data can honestly support, and both tools become considerably more useful than the accuracy debate suggests.

Disclosure: Some links in this article maybe affiliate links. If you purchase through them I may earn a commission — at no additional cost to you. This article reflects genuine practitioner experience with the tools discussed. Affiliate relationships don’t influence the analysis, including where I’ve been critical.